The Prisoner's Dilemma (PD) shows up in both game theory and evolutionary dynamics as a game which motivates the questions of 'when is cooperation a good idea' and 'why is cooperation sometimes selected for'. The idea is that you have two separated prisoners involved in the same crime who are each given two choices:
1) confess to the crime, thus defecting against your friend
2) keep your mouth shut, thus cooperating with your friend
There are three possible outcomes:
1) if both prisoners cooperate (stay quiet), they both get a year in prison
2) if both prisoners defect (confess), they both get 7 years in prison
3) if one prisoner cooperates whilst the other defects, the cooperative prisoner gets 10 years and the defector gets no years
This can be described in payoff-matrix form where the row = your choice and the column = their choice:

Let's say they cooperate (remain silent). If you defect you go free, whereas if you cooperated you'd get a year in prison
Let's say they defect. If you defect you only get 7 years in prison, whereas if you cooperated you'd get 10.
No matter what the other prisoner chooses, it is rational for you to defect in order to minimise your sentence. When there is a set of strategies that can be played with no player having any good reason to switch strategies, it's called a Nash Equilibrium. So in this case, defect-defect is a Nash Equilibrium because either player could only do worse by switching to cooperation.
What would happen if we applied a similar game to a population whose fitness is dependent on how the outcome of the game.

The fitness of a species is an indication of how fast its frequency increases, and it's given by:


which can be read as 'the rate at which a species frequency changes with respect to time is given by that species frequency times the difference between its fitness and the average fitness across all species'. So phi(x) represents the average fitness. This is intuitive due to the species increasing its frequency if it has an above-average fitness. So if the fitness of a species is equal to the average, its frequency won't change, and if its fitness is greater than the average, its frequency will rise, and otherwise it will fall.
Considering the replicator equation we can see what happens when we have a population of C's and D's. If we start with a 50/50 split in the population, the average fitness is 3x/2 + (4x+1)/2 = (7x+1)/2. Clearly the D's have a fitness above the average so they will be increasing their frequency and the C's will thus tend to a frequency of 0. At that point, when x = 0, the population will be in equilibrium with the replication rates all being 0 (because there's no more C's). BUT what if we started off with x = 1 i.e. there are no D's? This means now the average fitness is just the fitness of C's which is 3x and so the population won't change meaning this is another equilibrium point. The difference between the two equilibrium points is that the first is a 'stable' equilibrium, meaning small deviations from it will be corrected as the system naturally tends back towards the equilibrium point, whereas the second is not a stable equilibrium, as for example if you were to add a minuscule amount of D's to the mix, their superior strategy against cooperators would have them easily invade the population and move the frequency of C's down from 1.
The things I'm describing here can be represented by a simplex which is the set of all points which describe the frequencies of each species in a population. If we were only considering a population of one species, the simplex would be 0-dimensional i.e. it would be a single point. Because we're dealing with two species, we have a line:

Considering the only thing which effects this simplex is the payoff matrix, let's take a payoff matrix with payoffs a,b,c and d and see what kind of simplex we get depending on their relative values, with the species A and B (this time x = frequency of A's):

So the fitness of A = ax + b(1-x) and the fitness of B = cx + d(1-x)
the average fitness is:
x(ax + b(1 - x)) + (1 - x)(cx + d(1 - x))
and the replicator equation for A is:
x((ax+b(1-x))-x(ax + b(1 - x)) + (1 - x)(cx + d(1 - x)))
= -x(x-1)(x(a - b + c - d) + b + d)
And yes, I used a calculator for that.
We can now consider what happens for various relative values of a,b,c and d.
So let's say a > c and b > d. This means that no matter what A will dominate over B because it always gets a higher payoff and thus has a higher fitness than average while there's still B's floating around.
If it's the other way around and a < c and b < d then B will dominate over A.
If a > c but b < d then we can consider three situations:
1) there aren't many A's to start with so despite A's getting a better payoff against other A's than B's, there aren't enough A's for that to make a difference as the majority of games will occur between A's and B's in which case the B's destroy the A's, meaning the A's go extinct.
2) there aren't many B's to start off with, and the exact same logic applies: the B's will go extinct
3) there is a sweet spot where there are just enough A's and just enough B's for them to be in equilibrium, albeit an unstable one. To work out where this is you can solve A's replicator equation for when the rate of its changing frequency is 0 and you end up with x = (d-b)(a-b-c+d).
if a < c and b > d then each species gets a better payoff when interacting with the other species than interacting with their own species. This means we get a trend towards the middle of the simplex at a stable equilibrium. The position of that equilibrium is x = (d-b)/(a-b-c+d). The multiplication from above becomes a division, WHAT A TIME TO BE ALIVE (that's not sarcasm).
Finally, if a = c and b = d then it's impossible for selection to discriminate against either species because they are identical in their payoffs. This would give you a neutral simplex where no frequencies change but this is actually not accurate in terms of finite populations as neutral drift is enough to eventually wipe out one or the other species.
Here's a pictorial representation:

So we've looked at populations with two species. Before we go into more depth in the prisoners dilemma, let's consider what the implications of having three species are. As 1 species in a population gives us a 0D simplex i.e. a point, and then we get a line, now we get a triangle (the next step would be a triangular pyramid and then the dimensions go beyond what can easily be visualised). Let's consider the game of scissors paper rock (S,P and R) which has the quality that S dominates P, P dominates R and R dominates S. Here's the payoff matrix A:


Then we can work out what the simplex will look like. If the determinant is =0 then we have the neutral oscillation situations from the traditional SPR game. If it's <0 then we've still got the interior equilibrium point (whether it's actually in the centre depends on the matrix) but it's unstable and all other points spiral out towards the edges asymptotically so the boundary of the simplex is an attractor (called the heteroclinic cycle). If the determinant is >0 then we have the spiral but this this time the interior equilibrium point is the attractor (so it's stable).

Now that we have some intuition behind how a population works with three species, let's go back to the prisoners dilemma. The two strategies we had were Defect and Cooperate, but these alone don't tell us much about how species behave. What would be more accurate is if two individuals interacting with eachother played the game on average m times. Now the number of strategies really open up. The multi-game analogue of the single-game defect strategy would be the always-defect strategy (ALLD). Likewise we have the always-cooperate strategy (ALLC). The third strategy we're going to look at it tit-for-tat (TFT). In TFT, your first move is to cooperate and after that you just do what your opponent did in the previous round. This time we're going to use a generalised payoff matrix for a single round with the variables T,R,P and S where T>R>P>S. You can remember them as Temptation to defect, Reward for cooperating, Punishment for mutual defection and Sucker's payoff for being the one who cooperates when the opponent defects.
Let's consider how these strategies to eachother:
ALLD vs ALLC: ALLD wins because in each round it gets the highest payoff T, and ALLC gets the lowest payoff S.
ALLC vs TFT: both get the R payoff, which is a big step-up for ALLC but neither strategy walks away with as much of a payoff as ALLD when it's up against ALLC
ALLD vs TFT: TFT starts off cooperating and gets the Sucker's payoff whilst ALLD gets the Temptation payoff but after that TFT just defects for the rest of the m-1 round so TFT walks away with S + P(m-1) and ALLD walks away with a slightly higher payoff T + P(m-1).
ALLC vs ALLC: both get a pretty good R payoff each round.
TFT vs TFT: same as above
ALLD vs ALLD: measly payoff of P each round.
We can make this more interesting (and more accurate) by giving TFT a complexity cost 'c' which is subtracted from its total payoff in each iteration. This means ALLC will now beat it and ALLC-ALLC interactions yield higher payoffs than TFT-TFT interactions.
as you can see, ALLD always wins against its opponent. HOWEVER, two ALLDs versing each other get a far lower payoff than interactions between TFTs and ALLCs. What does this mean? If we start with (1/3,1/3,1/3) frequencies then ALLD is going to dominate but as its frequency increases, its fitness decreases because there are less TFTs and ALLCs to fight. Meanwhile the TFTs fitness increases because TFT is only slightly outplayed by ALLD but gets high payoffs with all other interactions. So we'll see a growth of TFT and a shrink of ALLD. But now with less ALLDs floating around, ALLC can once again rise as it fairs better than TFT in a population low in ALLDs. But then we get back to the beginning where ALLDs can exploit the high numbers of ALLCs.
So we know we're going to get oscillations, but will they be neutral or inward/outward spirals? If we follow the convention of saying T = 5, R = 3,P = 1, and S = 0.1, m = 10 and c = 0.8, then we get a matrix like this:

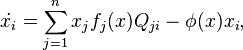
where Q is the matrix describing the probabilities of species j mutating to species i.
And here's some simplexes under this equation:

As you can see, this alone produces some crazy stuff. With very low mutation (u = 10^-8) we converge to the conventional replicator equation, and we can see that ALLD wins out in the end. Obviously with more mutation, the selection isn't as cut-throat so we see with u=10^-2 that there is a convergence to a stable equilibrium which has a high frequency of TFT. This is an interesting change which comes about through merely increasing the rate of mutation. Nonetheless the deterministic approach to the repeated prisoners dilemma overwhelmingly favours ALLD, which is intuitive due to ALLD-ALLD being the only nash equilibrium in the game. But is this what we see in finite populations?
The answer is no. In finite populations what we see is oscillations which have a time-average near the TFT vertex (i.e. most of the time is spent around there). Why is this the case? Good question. Finding out requires an understanding of how evolutionary dynamics works with finite populations, which has a whole lot of different processes (e.g. the Moran Process) and stochastic equations, but as this post has gotten long enough I'll leave you with the cliffhanger that finite populations and infinite populations can give us drastically differing results when simulating the same game.
Special thanks to Martin Nowak whose textbook on evolutionary dynamics provided a few of the images in this post a lot of insight into how evo-dynamics works.